Text Analysis Platform
At Ozora Research, our goal is to build software systems that understand text. In contrast to most other NLP research, our work focuses emphasizes the importance of empirical knowledge of text, instead of relying only on machine learning algorithms. This page describes some of the knowledge we've accumulated in our work. We are excited to help people take advantage of this knowledge, by using our search features, our APIs, or with consulting projects.
Link Grammar Parser
At the core of our NLP system is a sophisticated grammar formalism that is based on the idea of Link Grammar. In a Link Grammar sentence description, every word is connected to its parent or head word, with a label designating the type of the connection. For example, in the sentence "The man bought a new car", the word "man" is connected to "bought" with a subject role, while "car" is connected to "bought" with an object role.
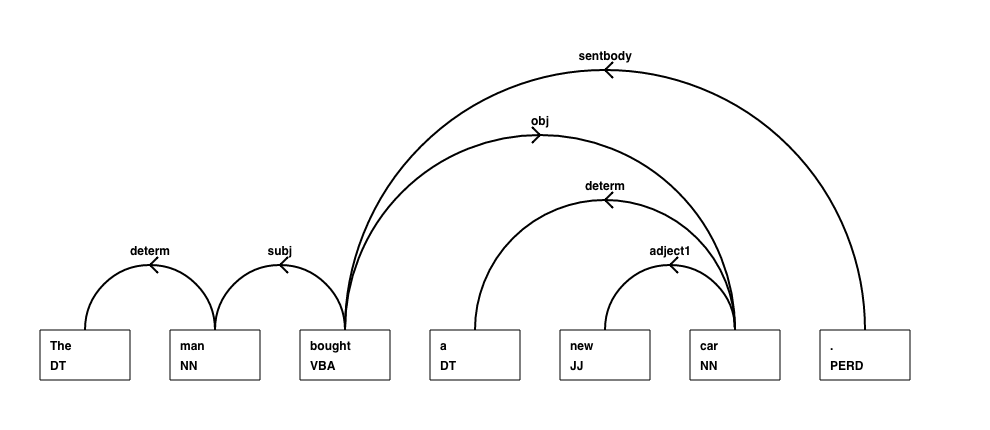
To complement our grammar formalism, we've built a sentence parser that automatically constructs the parse linkage for an input sentence. The parse linkage can then be used as a way to determine the meaning of the sentence. The parser works by exploiting a combination of knowledge-based syntactic rules and statistical analysis (machine learning) algorithms trained on a large, unlabeled text corpus.
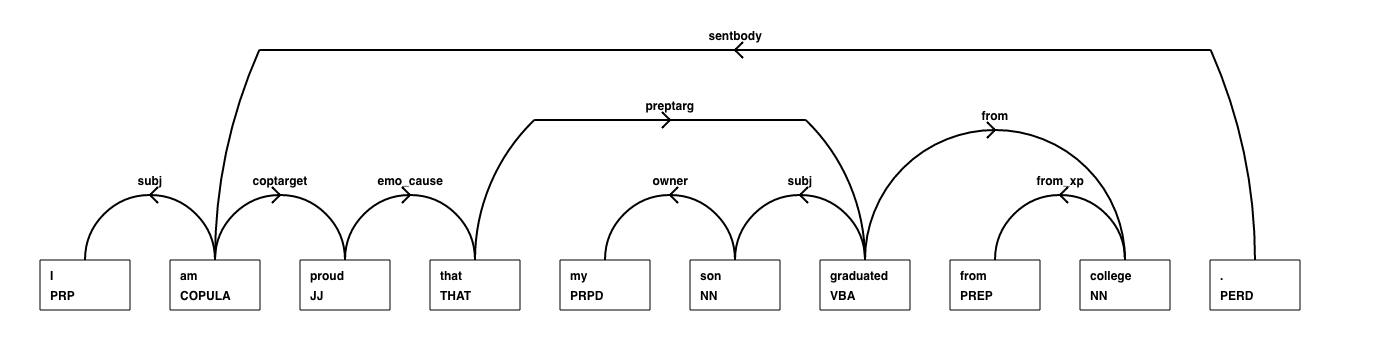
Our formalism goes far beyond basic linguistic concepts like subject and object. Our grammar includes knowledge about relative clauses, possessive phrases, questions, and many other constructs. One of our first discoveries was that English text cannot be described well by any simple, short list of grammatical rules. Instead, grammar is like vocabulary, which is characterized by Zipf's Law (also called the Power Law, Pareto Principle or 80/20 rule). The most common rules account for the bulk of the structures, but in order to understand text well, a system must have good working knowledge of the "Long Tail" of less common rules. A good example of a Long Tail rule relates to emotion adjectives, like "proud" or "happy":
- I am proud that my son graduated from college.
- She was happy to be back in Boston.
In these sentences, the emotion adjective connects to a that-complement ("that my son...") or an infinitive phrase ("to be back..."). This connection designates the cause of the emotion. This kind of interpretation is unique to emotion adjectives; you cannot say "The trees are yellow that it is autumn". In order for an NLP system to understand these sentences correctly, it must 1) know about the existence of this emotion-related rule and 2) have a dictionary in which the emotion adjectives are specially marked.
You can try out the sentence parser here, or look at some examples from our Sentence Gallery.
Entity Management
One of the central themes in serious non-fiction writing is constant reference to Entities. Newspaper articles describe the interactions between people, companies, government agencies, places, laws, events, and so on. In order to understand the meaning of the text, a system must possess substantial knowledge of Entities.
Part of the problem is that Entities can appear in multiple different forms. For example, authors often use the acronym "FDA" to stand for the "Food and Drug Administration". Similarly, the strings "Hillary Clinton", "Mrs. Clinton", or just "Clinton" might all be used to designate the same person. To extract the maximum information value from the text, we need to be able to resolve these variant forms to the same unique Entity.
Another challenge for Entity analysis is simply the management of large amounts of Entity-related information. While it is usually easy to identify that a particular string represents an Entity, it is more challenging to connect the string to a larger universe of knowledge related to a specific Entity. For example, consider the following sentences (from here)
- The two companies are in talks to structure a deal in such a way that Allergan would be acquiring Pfizer.
It is relatively easy to identify the strings "Allergan" and "Pfizer" as Entities, but unless the NLP system has a large Entity database, it will have no way of knowing that these strings refer to companies in the pharmaceutical industry.
At Ozora, we've done a substantial amount of work in building an Entity database, that is fed by data pipelines from various sources such as WikiPedia (people, companies, places), IMDB (movie and TV), and the FDA (drug names). Our Entity Management system pulls the data from these sources, and then formats and post-processes it into a consistent, useable form. The technology depends partly on smart heuristics and automation, and partly on efficient human curation tools.
The Ozora system also has different components that understand the micro-grammar associated with different types of Entities (people, company, place, etc). For example, the system knows that the word "California" is often abbreviated as "Calif." This enables the system to resolve different string forms to the same Entity.
Lexical Knowledge
A crucial part of good text analysis is lexical knowledge: information about words. For example, one important aspect of English text is morphology, the process by which words are transformed using suffixes or prefixes. The word "unoperationalizable" is formed from the root word "operate" by applying a prefix and four suffixes (-ion, -al, -ize, -able). The Ozora system knows this, and can conclude that the word is an adjective, since the -able suffix is used to create adjectives from verbs. The system also knows about alternate spellings, so it knows that the string "recognisable" is just a variant of "recognizable".
Another important type of lexical knowledge is argument structure. The argument structure of a word is a description of the types of grammatical substructures to which it can connect. In contrast to simple verbs such as "eat" and "run", the verb "persuade" has a special property that allows it to attach to a that-complement:
- I persuaded him that the opportunity was real.
Linguists often talk about argument structure in relation to verbs, but it is also relevant to nouns and adjectives. For example, words like "right" or "decision" can take an infinitive complements:
- Immigrants demanded the right to vote.
- The decision to fire the company president was made too hastily.
Obviously, knowledge of argument structure can be very useful in parsing. The Ozora system makes use of this kind of knowledge to improve parsing accuracy.